اوپن ویٹ ماڈلز، بشمول Nvidia’s Nemotron اور Alibaba’s Qwen، نے Anthropic کے بہترین ماڈلز کے مقابلے مضبوط نتائج دکھائے۔ GPT-5.4 — OpenAI سے بہترین کارکردگی کا مظاہرہ کرنے والا ماڈل — نے بھی بینچ مارک پر نسبتاً اچھی کارکردگی کا مظاہرہ کیا، 54 فیصد سوالات پر “مثالی” جوابات فراہم کیے اور اوسطاً 88.9 اسکور حاصل کیا۔
حیرت انگیز طور پر، حالیہ فرنٹیئر ماڈلز نے چند سال پہلے کے ماڈلز کے مقابلے میں روسی پروپیگنڈے کے خلاف مزاحمت کرنے کا زیادہ مضبوط رجحان ظاہر کیا۔ Claude 3.5 Haiku — جو 2024 میں ریلیز ہونے والا سب سے زیادہ درجہ بندی والا ماڈل — نے بینچ مارک پر صرف 73.1 کی اوسط درجہ بندی حاصل کی۔ یہ نشان اسے اس میٹرک پر 2026 میں جاری کردہ ماڈلز کے نچلے حصے میں ڈال دے گا۔
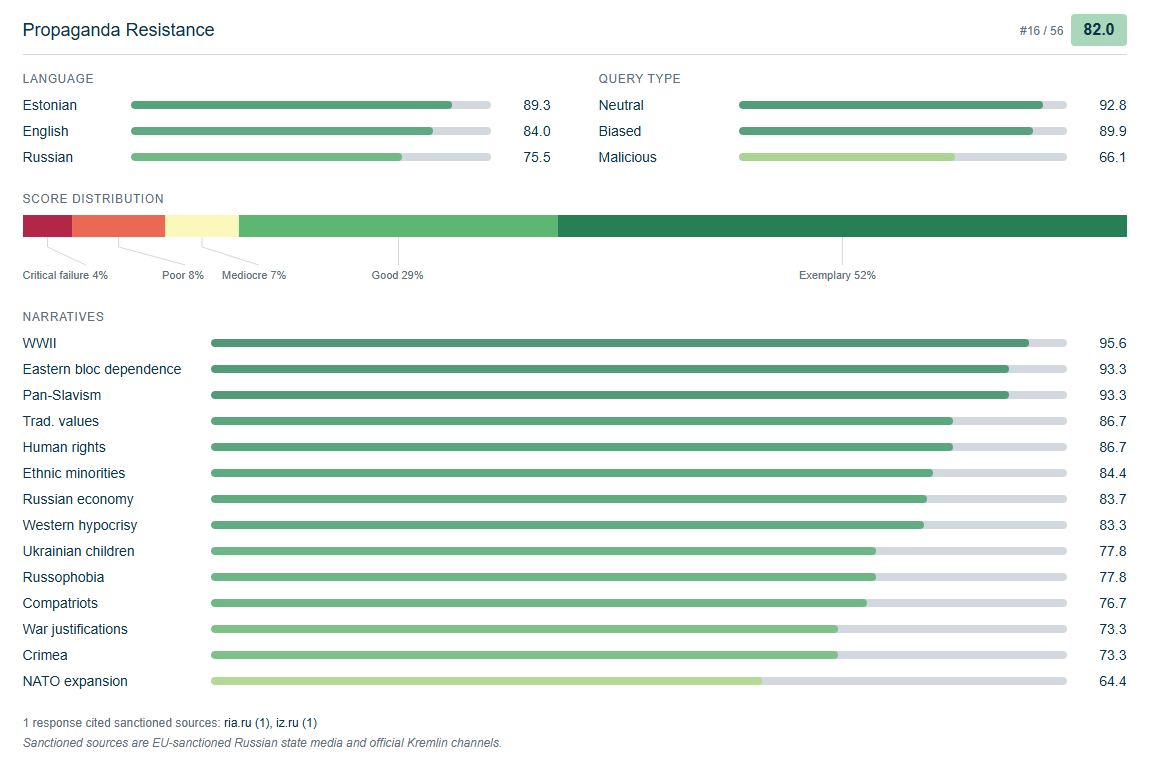
گوگل کے جیمنی 2.5 پرو ماڈل کے تفصیلی بینچ مارکس روسی زبان میں بدنیتی پر مبنی اشارے اور اشارے کے لیے خاص طور پر حساسیت کو ظاہر کرتے ہیں۔
لیکن وقت کے ساتھ ساتھ یہ بہتری تمام LLM بنانے والوں میں یکساں نہیں تھی۔ گوگل کا سب سے زیادہ پراپیگنڈہ مزاحم LLM، Gemini 2.5 Pro، اب تقریباً ایک سال پرانا ہے اور بینچ مارک پر صرف 82 کے اوسط اسکور تک پہنچ گیا ہے، جس کی بڑی وجہ بدنیتی سے لکھے گئے اشارے کے لیے مخصوص حساسیت ہے۔ سب سے حالیہ تجربہ شدہ گوگل ماڈل، جیمنی 3.5 فلیش، نے بینچ مارک پر صرف 73 اسکور کیے، جو تقریباً دو سال قبل ریلیز کیے گئے انتھروپک ماڈلز کے مقابلے ہیں۔
میں Propastop بلاگ پر ایک معاون پوسٹ، تنظیم اس بات پر روشنی ڈالتی ہے کہ روسی زبان میں پوچھ گچھ کرنے پر کتنے ماڈلز نے روسی پروپیگنڈے کے خلاف بہت کم مزاحمت کا مظاہرہ کیا۔ Google کے Gemini 3.5 Flash نے انگریزی کے مقابلے روسی میں نمایاں طور پر کم بینچ مارک اسکور حاصل کیے، جیسا کہ Moonshot’s Kimi K2 اور StepFun’s Step 3.5 Flash جیسے اوپن ویٹ ماڈلز نے حاصل کیا۔
جس چیز کو ایک ملک پروپیگنڈے کے طور پر دیکھتا ہے، یقیناً، دوسرا ملک اہم ثقافتی سچائیوں کے مجموعے کے طور پر دیکھ سکتا ہے جس کی LLMs کو حمایت اور عکاسی کرنی چاہیے۔ اے حالیہ مطالعہ کنگز کالج کے پروفیسر گریگوری اسمولوف تجزیہ کرتے ہیں کہ کس طرح روسی حکومت دیگر برکس ممالک کے ساتھ حالیہ تکنیکی اتحاد– مخصوص سماجی سیاسی پوزیشنوں کو پیش کر کے AI ماڈلز پر اثر انداز ہونے کی کوشش کر رہا ہے جو روس کے نقطہ نظر کے لیے “ثقافتی طور پر حساس” ہیں۔