
ایک اور دن، گوگل کا ایک اور اے آئی ماڈل۔ اس بار گوگل ڈیپ مائنڈ نے ایک نیا ممبر جاری کیا ہے۔ جیما 4 اوپن ماڈل فیملی، لیکن یہ باقی لائن اپ سے بنیادی طور پر مختلف ہے۔ DiffusionGemma زیادہ تر AI ماڈلز کی طرح لکیری طور پر آؤٹ پٹ پیدا نہیں کرتا ہے۔ اس کے بجائے، یہ متوازی طور پر متن کا ایک پورا بلاک تیار کر سکتا ہے۔ گوگل کا کہنا ہے کہ مقامی ہارڈ ویئر جیسے Nvidia DGX یا ایک شائستہ گیمنگ GPU پر چلتے وقت یہ اسے تیز تر اور زیادہ موثر بناتا ہے۔
زیادہ تر AI ماڈلز کو خود بخود ہونے کے لیے ڈیزائن کیا گیا ہے — وہ ایک وقت میں بائیں سے دائیں ایک ٹوکن متن تیار کرتے ہیں۔ DiffusionGemma امیج جنریشن ماڈلز کے ساتھ زیادہ مشترک ہے، جو جامد سے شروع ہوتے ہیں اور پھر مطلوبہ مواد بنانے کے لیے اس کی تردید کرتے ہیں۔ یہ ماڈل ممکنہ ٹوکن تیار کرنے اور دوسروں کے تخمینے کو بہتر بنانے کے لیے استعمال کرنے کے لیے کینوس پر کئی بار چلنے والے پلیس ہولڈر ٹوکنز کا ایک فیلڈ لیتا ہے۔ عمل کے اختتام پر، ماڈل اپنے ٹوکن آؤٹ پٹس کو ایک بڑے بلاک میں حتمی شکل دیتا ہے – “منکر” ٹیکسٹ کینوس۔
DiffusionGemma گوگل کے کھلے ماڈلز کے دائرے میں کافی بڑا ہے۔ یہ ماہرین کا مرکب (MoE) ماڈل ہے جس میں کل 26 بلین پیرامیٹرز ہیں، لیکن تخمینہ کے دوران صرف 3.8 بلین کو چالو کیا جاتا ہے۔ اس کا مطلب یہ ہے کہ یہ ایک اعلیٰ درجے کے GPU کے 18GB رام الاٹمنٹ میں فٹ ہونا چاہیے۔ RTX 5090 کے ساتھ ٹیسٹنگ میں، DiffusionGemma تقریباً 700 ٹوکن فی سیکنڈ نکالتا ہے۔ ایک Nvidia H100 AI ایکسلریٹر کے ساتھ، DiffusionGemma فی سیکنڈ 1,000+ ٹوکن تیار کر سکتا ہے۔ یہ اسی طرح کے سائز کے آٹوریگریسو جیما ماڈلز کی پیداوار کا تقریباً چار گنا ہے۔
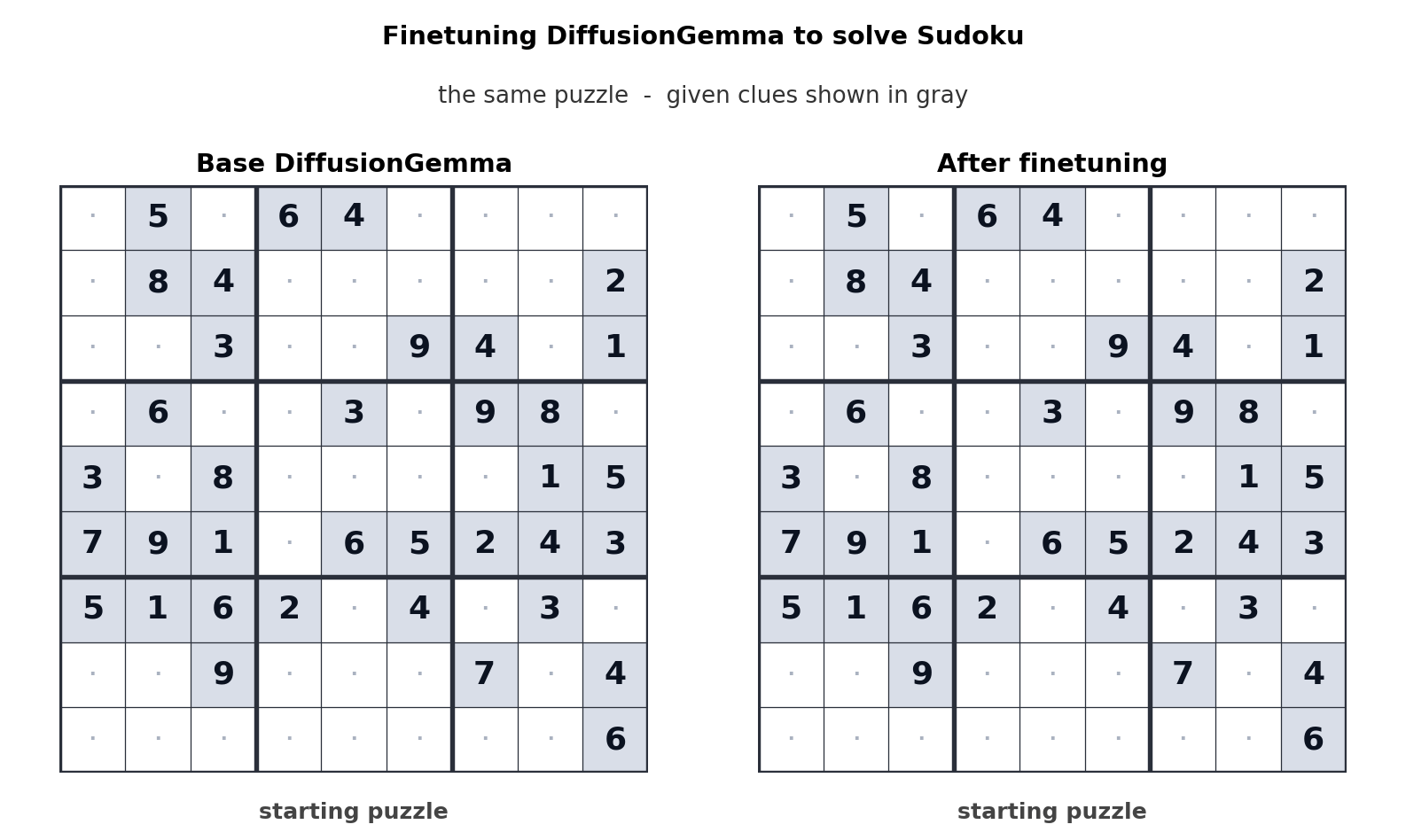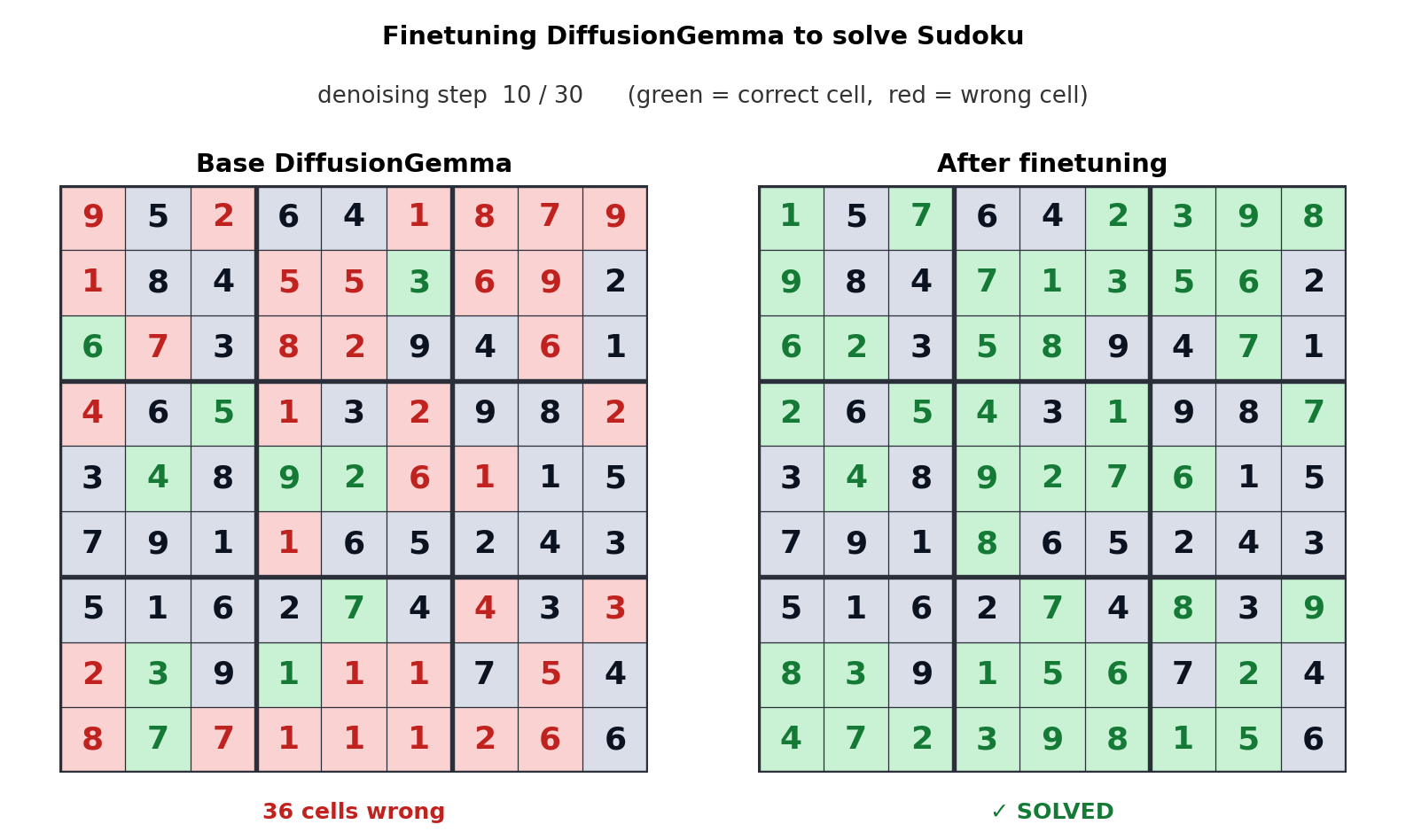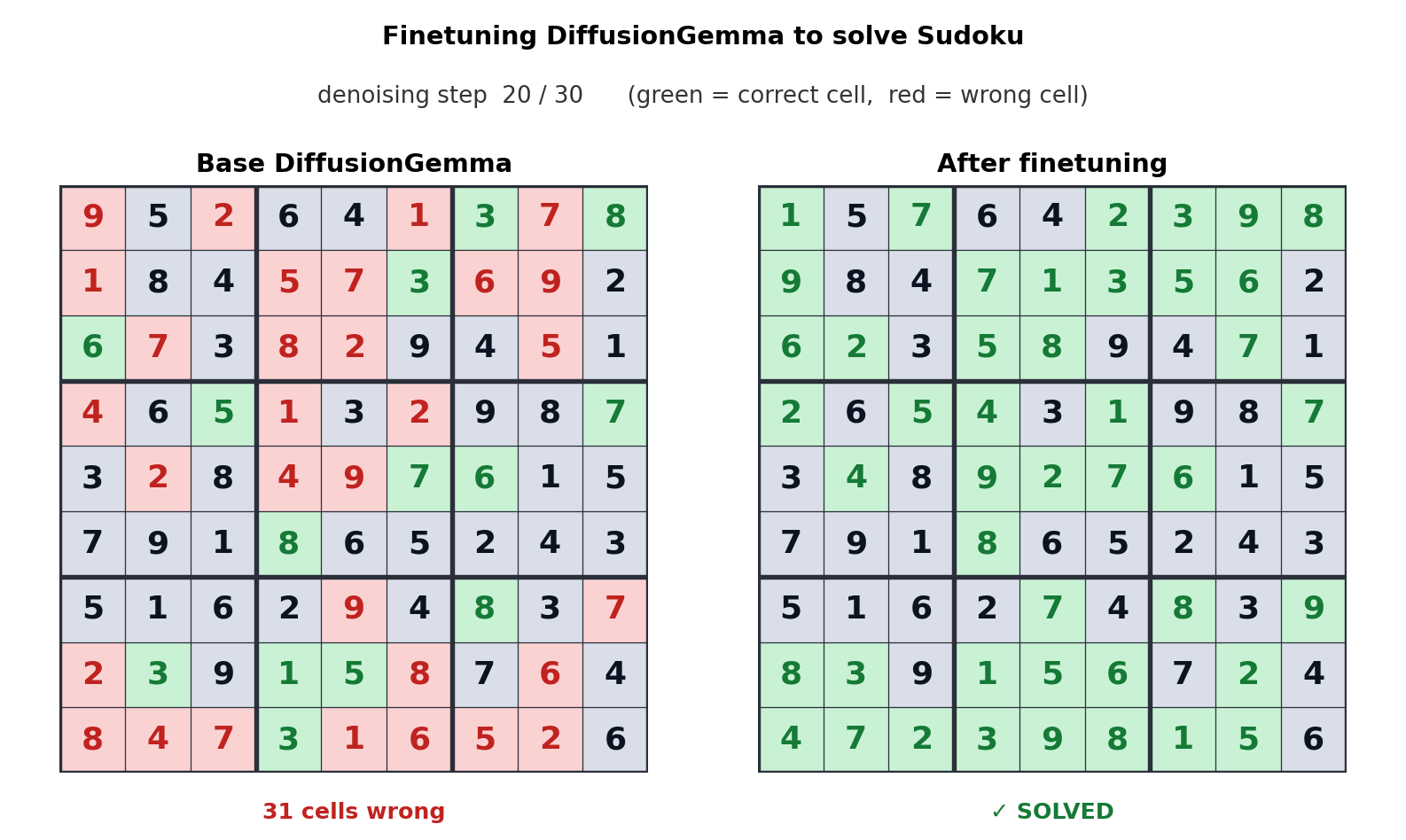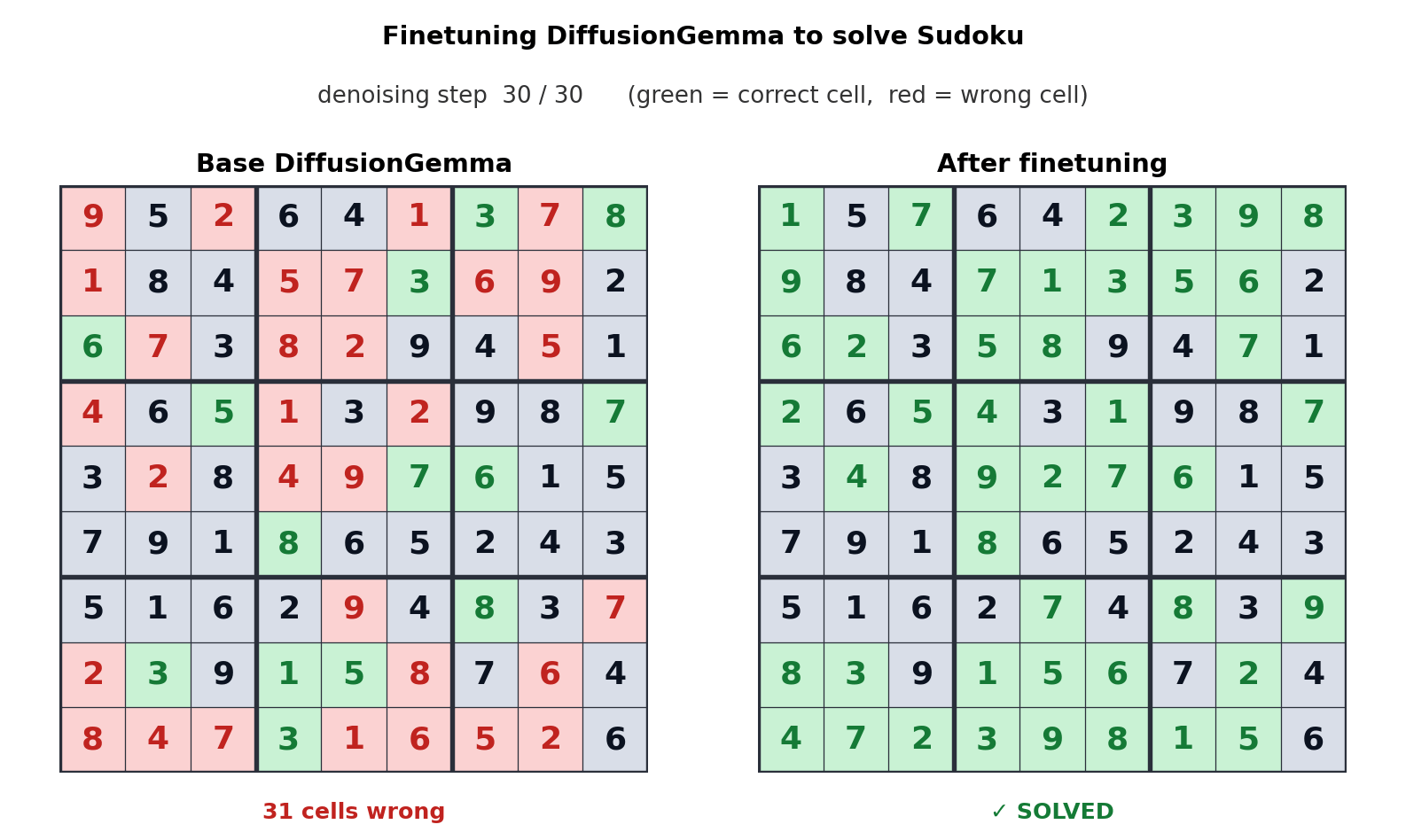
ٹیکسٹ جنریشن کے لیے یہ نقطہ نظر رکاوٹ کو میموری بینڈوڈتھ سے کمپیوٹ میں منتقل کرتا ہے، جس سے متوازی طور پر 256 ٹوکن پیدا ہوتے ہیں۔ گوگل کا کہنا ہے کہ یہ ان لائن ایڈیٹنگ، مالیکیولر سیکوینسنگ، اور ریاضیاتی گرافنگ جیسے غیر خطی کاموں میں قابل پیمائش فروغ پیش کرتا ہے۔ مندرجہ بالا اینیمیشن سے پتہ چلتا ہے کہ کس طرح سوڈوکو پہیلیاں حل کرنے کے لیے DiffusionGemma کو ٹیون کیا گیا تھا، جو معیاری آٹوریگریسو اے آئی ماڈلز کے لیے ایک انتہائی مشکل کام ہے کیونکہ ہر ٹوکن مستقبل کے ٹوکنز پر منحصر ہے۔ DiffusionGemma کی ٹوکن کے بڑے سیٹوں کو مسلسل خود درست کرنے کی صلاحیت اسے آسان بناتی ہے۔


